When AI agents throw 500s: designing for agent failure

I run multiple products. Alone. The only way that math works is if monitoring is not a thing I do.
Last quarter I built a monitoring platform, which I usually just call flatnine-health: the single dashboard for every metric across every FlatNine product. Heartbeats, application errors, uptime checks, slow pages, database metrics, server metrics. Everything that used to live in five different dashboards (or worse, in nobody's dashboard at all) flows into one place.
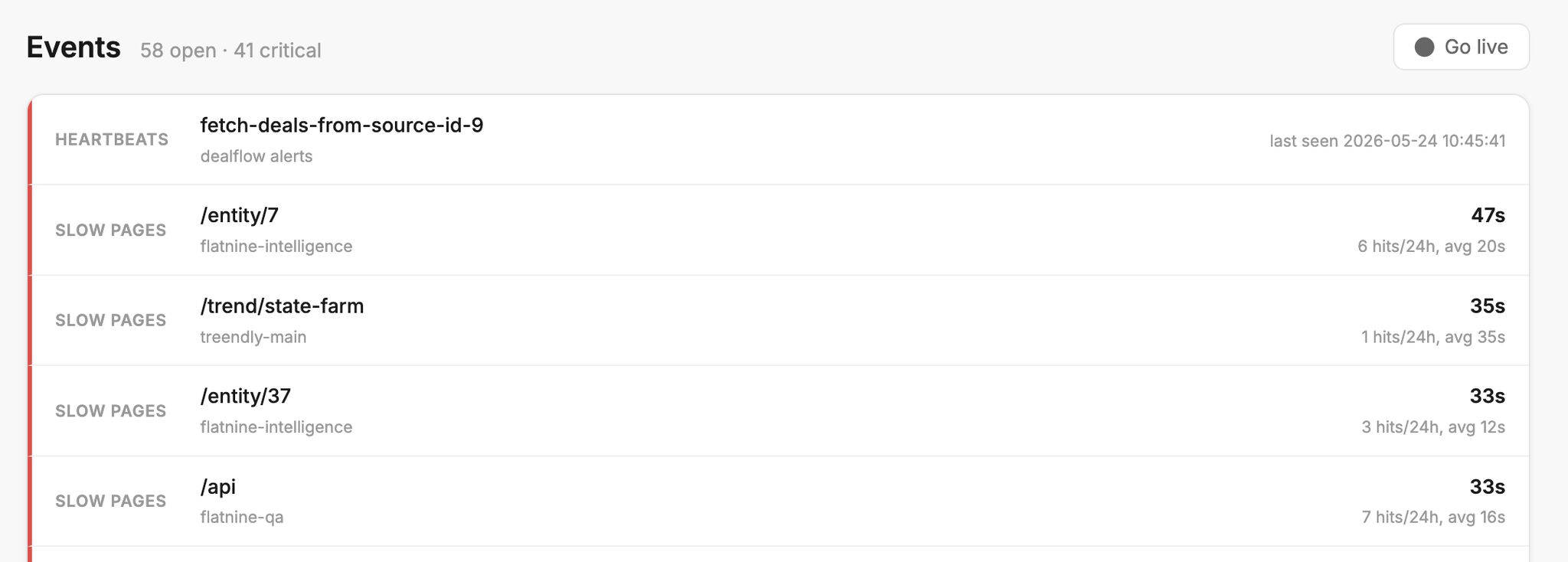
The dashboard is half the story. The other half is Herbie.
The problem with monitoring as a human
A monitoring dashboard is only useful if a human is looking at it. The dirty secret of every observability product I have ever paid for is that they all assume a person opens the dashboard, scans it, notices something is off, and decides what to do. That model breaks at one product. At many it is a fantasy.
Heartbeats miss. Cron jobs silently fail. A page that used to load in 200ms slips to 4 seconds because somebody (me) added an N+1 query and the dataset finally grew enough to bite. A database connection pool drifts past its limits at 3am. A server runs out of disk because a log rotation rule never got tightened.
None of those things page me. None of them email me. They quietly degrade the products until a customer notices, which is far too late.
Herbie
Herbie is the AI developer agent who does my engineering work. He has the same toolchain I do: he reads the code, runs the tests, writes commits, opens PRs. The difference is that he never sleeps, and he is allowed to start deep tasks on his own.
flatnine-health is one of the things that wakes Herbie up.
Every metric in the dashboard is wired to a threshold. When a threshold trips, the event does not become an email or a Slack alert. It becomes a task. Herbie picks it up, pulls the relevant logs, reads the relevant code, forms a hypothesis, and (this is the part that matters) tries to fix it.
A few of the patterns Herbie handles end-to-end:
- A heartbeat for one of the cron jobs stops firing. Herbie checks the SQLite write permissions, notices the file ownership drifted after a server move, fixes the chmod, reruns the job. The dashboard goes green before I wake up.
- A page p95 crosses 2 seconds on one of the apps. Herbie traces it to a missing index on a join, writes the migration, runs it against staging, and opens a PR with the before-and-after timing in the description.
- A spike in 500 errors correlates with a deploy that morning. Herbie diffs the deploy, finds the null reference in a new code path, writes a regression test, and opens the fix.
None of those involve me until the PR is in my queue.
Why the dashboard had to come first
You cannot point an agent at "fix the problem" if there is no consistent place where problems show up. The reason monitoring tools historically fragment (one for cron, one for errors, one for uptime, one for queries, one for the server itself) is that they each grew up in different eras and nobody bothered to unify them. That fragmentation is fine for a human, because a human can mentally bridge the gaps. It is fatal for an agent, because the agent's context is finite and you do not want it spending tokens figuring out which tool to ask.
flatnine-health is the cheap unification layer. It does not replace the underlying tools. It pulls from them, normalizes the events, and presents them as a single feed. The feed is what Herbie subscribes to. Once that feed existed, plugging Herbie in was a weekend.
Deep tasks, not notifications
The instinct, when you build something like this, is to wire alerts. A Slack ping. An email. A PagerDuty escalation. I used to have all of those. They were noise.
A deep task is different. It is a self-contained piece of work with its own context window, its own toolchain, and its own definition of done. When flatnine-health fires an event, Herbie does not get an alert. He gets a task. The task says: here is the metric that tripped, here are the relevant logs from the last hour, here is the code path that probably matters. Fix it, or explain why you cannot.
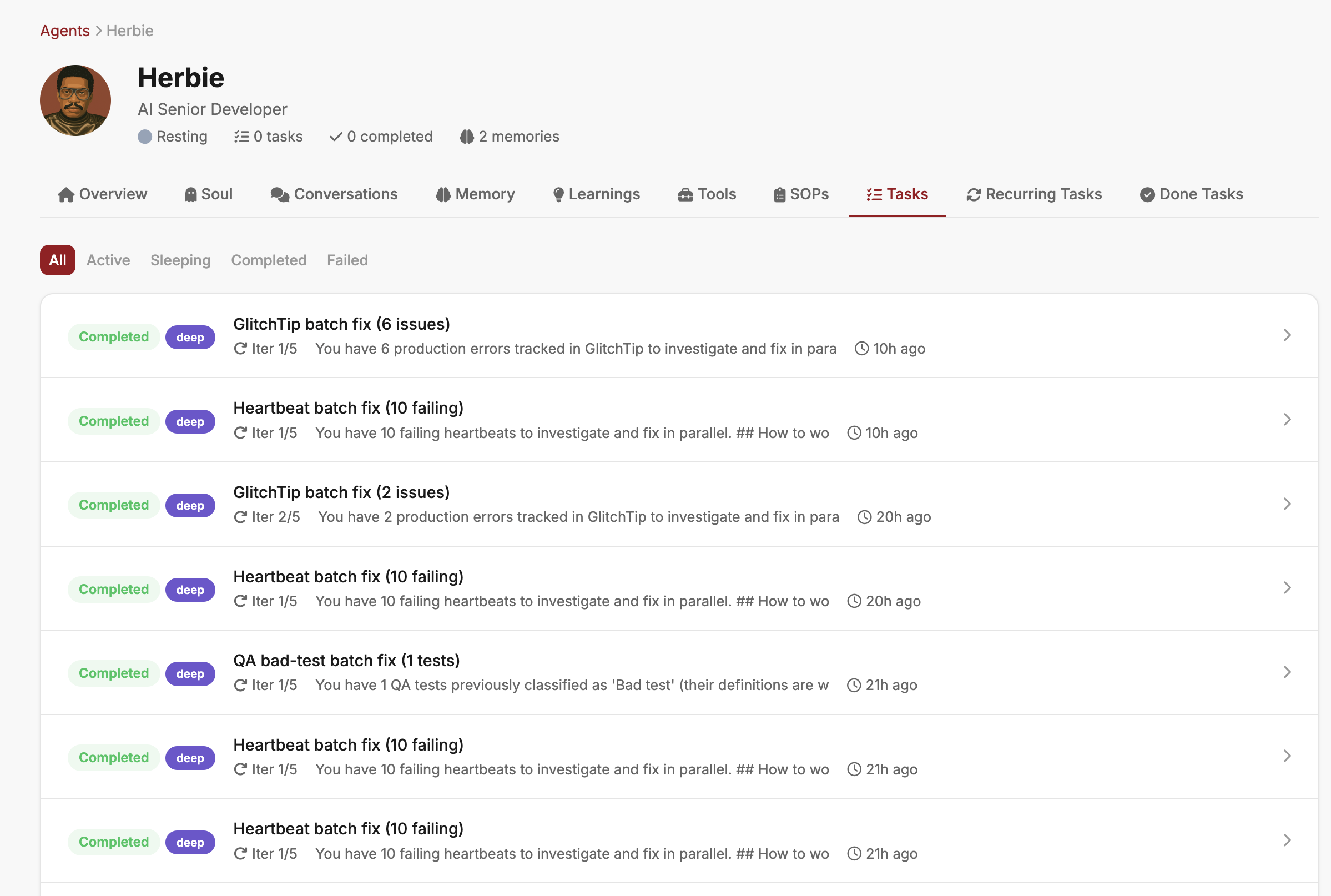
If he can fix it, he fixes it. If he cannot, he writes up what he found and hands it to me with the context already pre-loaded. Either way, I never get the half-baked middle state of "something is wrong, you figure it out."
What this changes about running a portfolio
Running multiple products used to be a series of small fires I would eventually notice. Now it is a stream of PRs in my queue, each one labeled with the metric that caused it, the hypothesis, the fix, and the rollback plan. I review, I merge, I move on.
I am not pretending this is fully autonomous. Herbie still hands me the things he is unsure about, and those are mostly the ones I want to look at anyway: schema changes, anything touching billing, anything that smells like a privacy issue. The boring 80% (a missing index, a permissions glitch, a typo'd config) closes itself.
The pitch for AI in operations was always supposed to be this. A junior engineer who never sleeps, watches every metric, fixes the obvious stuff, escalates the rest. The reason it never quite worked before was that the monitoring layer was too fragmented to point an agent at. Now it is not.
flatnine-health is the substrate. Herbie is the agent. The thing they produce together is a portfolio that runs while I write the next product.
Part of a series on building FlatNine Ensemble, a team of AI agents that runs a business. Related: AI observers, Evaluating AI work, Lossless orchestration.